Datenbank oder statisch
Lange Zeit haben wir in einer Welt gelebt, in der wir Standardansätze verwenden, ohne vollständig über ihren Zweck nachzudenken. Nehmen wir WordPress als Beispiel: Es ist eine leistungsstarke Anwendung, aber sie erfordert MySQL als Datenbank und um es schneller zu machen, benötigt man oft Memcache, um MySQL-Abfragen zwischenzuspeichern und die Datenbanklast zu reduzieren. Daneben gibt es den WYSIWYG-Editor, der theoretisch Benutzern ermöglicht, HTML einfach zu bearbeiten, in der Praxis jedoch oft unleserlichen, aufgeblähten Code erzeugt.
Aber die zentrale Frage ist: Warum tun wir das? Wir installieren WordPress, MySQL und Memcache, um im Wesentlichen "statische" Seiten zu erzeugen, da WordPress langsam sein kann und Inhaltsaktualisierungen selten sind. Für jede generierte Seite:
- Eine einfache WordPress-Seite benötigt 10-30 Anfragen.
- Eine mittelkomplexe Seite mit einigen Plugins und einem beliebten Theme: 30-60 Anfragen.
- Eine hochkomplexe Seite mit vielen Plugins und schweren Themes kann 60-100+ Anfragen benötigen.
Sogar ein einfacher Blogbeitrag kann zwischen 10 und 100+ Anfragen erfordern, was erklärt, warum WordPress-Seiten langsam sein können.
Warum bleiben wir bei WordPress?
Die große Frage bleibt: Warum verwenden wir ein so kompliziertes System? Historisch gesehen machte die Verwendung einer relationalen Datenbank wie MySQL für einen Blog Sinn, da Menschen Kommentare hinterlassen konnten und Datenbanken eine schnelle Möglichkeit boten, diese Informationen zu speichern und abzurufen. Aber heute haben nur wenige WordPress-Seiten Kommentare aktiviert, aufgrund des endlosen Spams, der sie oft begleitet. Infolgedessen verlassen sich die meisten Seiten auf Drittanbieter-Lösungen wie Disqus oder Facebook Comments, um Benutzerkommentare zu verwalten. Diese Dienste übernehmen die Benutzerverifizierung und Spamfilterung, was bedeutet, dass wir die Datenbank nicht mehr benötigen, um dynamische Inhalte in Form von Kommentaren bereitzustellen.
Ein statischer Ansatz
Bei True haben wir uns für einen komplett statischen Ansatz entschieden. Wir verwenden statische Dateien als unsere "Datenbank":
- blog.php verwaltet Blogseiten.
- support.php verwaltet Support-Seiten (historisch unterschiedlich, aber jetzt im Format ähnlich).
- categories.php verwaltet die Liste der Kategorien im oberen Menü und in der Seitenleiste.
Wir speichern die gesamte Blog-Datenbank als einfache PHP- oder JSON-Dateien, was effizient ist, da wir PHP verwenden, um unsere Seite zu betreiben.
So funktioniert es:
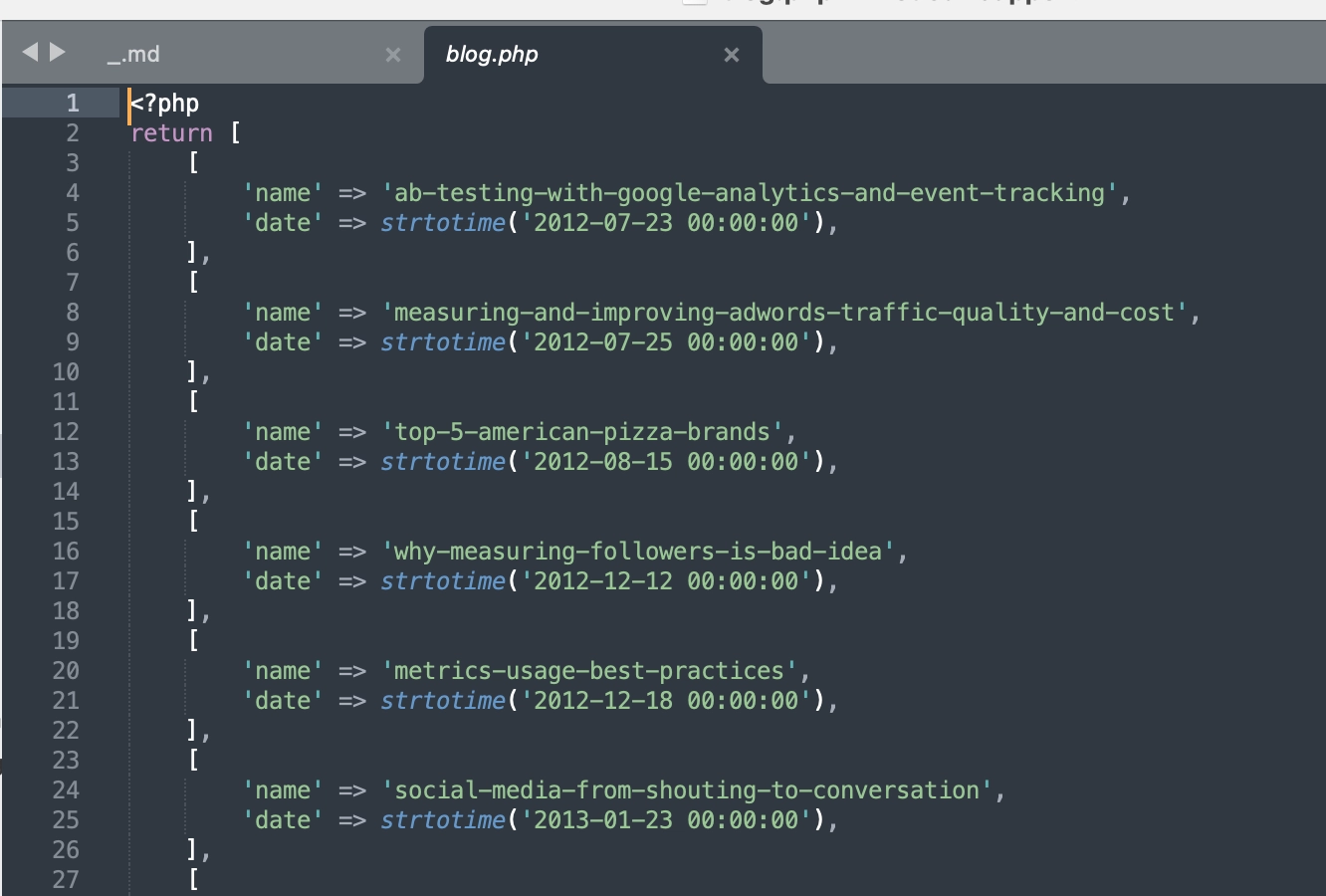
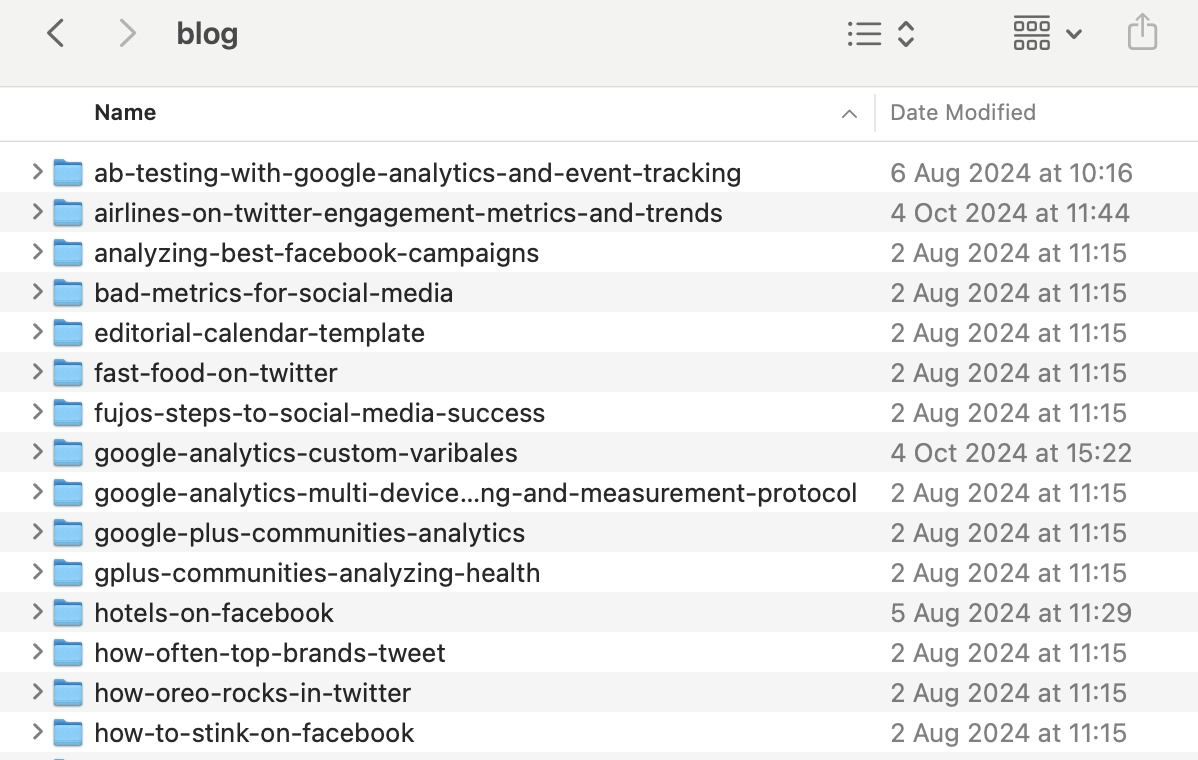
Jeder Blogeintrag wird als Ordner gespeichert, der eine Markdown-Datei (_.md) und zugehörige Assets wie Bilder und Anhänge enthält.
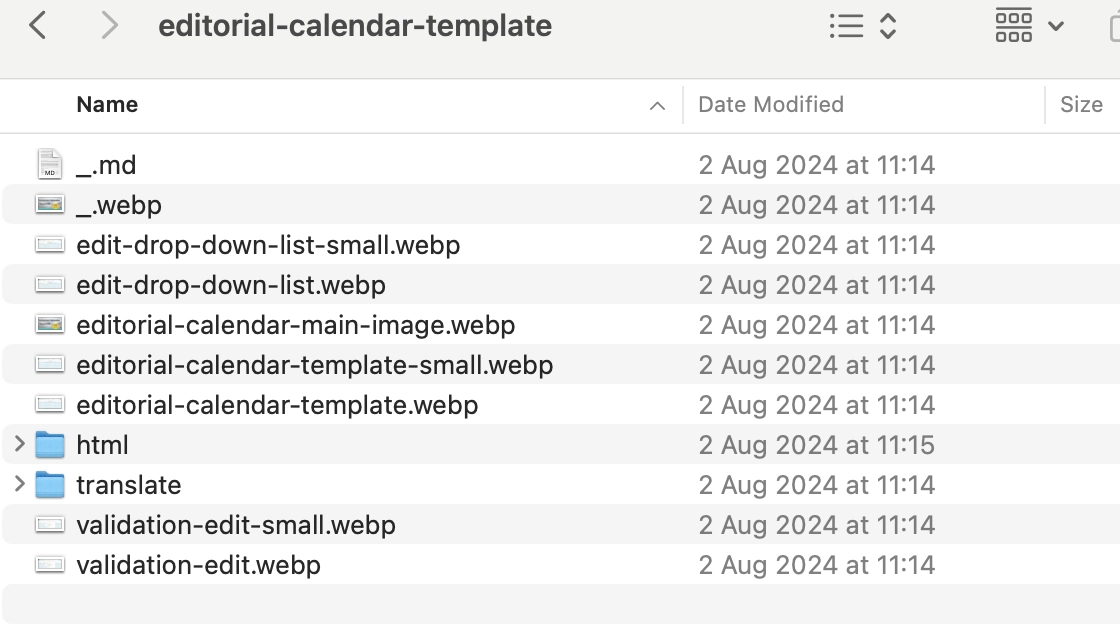
Wir haben auch zwei zusätzliche Ordner für:
- Translate: Speichert Übersetzungen der Markdown-Dateien in verschiedenen Sprachversionen (z.B. es_ES, de_DE).
- HTML: Enthält die aus Markdown generierten HTML-Dateien, die bei jedem Deployment neu generiert werden.
Das Besondere passiert während des Deployment-Prozesses. Wir verwenden Composer, um die Umwandlung von Markdown zu HTML durch Skripte auszulösen:
"scripts": {
"post-install-cmd": [
"php bin/markdown-to-html.php"
],
"post-update-cmd": [
"php bin/markdown-to-html.php"
]
}
Das beste Tool, das wir für die Markdown-Transformation gefunden haben, ist league/commonmark, welches nützliche Plugins mitbringt, einschließlich Tabellensupport und benutzerdefinierte CDN-Pfade für unsere Bilder.
Deployment
Wir verwenden einen Deployment-Prozess basierend auf GitHub Actions und Deployer, den wir leicht integrieren konnten. Hier ist ein Beispielskript:
name: Deploy
on:
push:
branches: [ "main" ]
concurrency: production_environment
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: "8.3"
- name: Deploy
uses: deployphp/action@v1
with:
private-key: ${{ secrets.PRIVATE_KEY }}
dep: deploy
verbosity: -vvv
Der Prozess ist einfach: Jedes Mal, wenn jemand in den "main"-Branch commitet, erfolgt die Bereitstellung automatisch. Die Aktionen während des Deployments umfassen:
- Kopieren von Bildern in den
public/img-Ordner. - Erstellen einer Hash-Tabelle für alle Bilder und Anhänge.
- Generieren von HTML aus den Markdown-Dateien durch:
• Korrigieren der Bildpfade (z.B. von
/img/blog/...zucdn.truesocialmetrics.com/img/blog/...). • Aktualisieren von CDN-Pfaden, wo nötig.
Während der HTML-Generierung werden Layouts, Header und Menüs ebenfalls hinzugefügt. So liefern wir statische Dateien aus, die für Benutzer dynamisch erscheinen können.
Vorteile eines statischen Ansatzes
Leistung
Statische Seiten sind unglaublich schnell, mit Ladezeiten von nur 3-5ms.
Einfachheit
Unser Support-Team in Markdown zu schulen ist viel einfacher, als ihnen die Navigation durch ein komplexes CMS wie WordPress beizubringen.
Sauberer Code
Indem wir den Markdown-zu-HTML-Transformationsprozess steuern, stellen wir sicher, dass der resultierende HTML-Code sauber und für Suchmaschinen optimiert ist (Hallo, Google!) sowie für Funktionen wie den „Reader View“ in Browsern.
Wartbarkeit
Da wir statische Dateien und Git für die Versionskontrolle verwenden, wird jede Änderung automatisch verfolgt, bis hin zu einzelnen Zeilen. Anhänge wie Bilder profitieren ebenfalls von der Versionskontrolle, sodass wir immer wissen, wer eine Änderung vorgenommen hat und warum. Dies macht das Suchen und Bearbeiten von Inhalten effizient, durch Werkzeuge wie grep und ack.
Team-Zugänglichkeit
Unser Team findet die statische Struktur einfach zu handhaben, besonders mit Tools wie GitHub Desktop und Typora, einem schönen und einfachen Markdown-Editor.
Fazit
Im Wesentlichen haben wir uns von dem traditionellen, datenbankgesteuerten Ansatz entfernt, der Plattformen wie WordPress dominiert. Durch die Verwendung eines statischen Systems haben wir nicht nur die Leistung verbessert, sondern auch die Wartung, Inhaltserstellung und Teamzusammenarbeit vereinfacht.
Wenn Sie bereit sind, Ihre Social-Media-Analysen zu rocken
Probieren Sie TrueSocialMetrics aus!
Testversion starten
Keine Kreditkarte benötigt.
Weiterlesen
Infografik: Welche sozialen Netzwerke sind am ansprechendsten

Lock-in Landing Pages – der Weg ins Nirgendwo

30-Tage-Tipps zur Verbesserung Ihrer Social-Media-Präsenz

10 winzige TrueSocialMetrics-Optimierungen, um mehr Zeit bei Ihrer Social-Media-Analyse zu sparen
